
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 엑셀에 ollama
- 빅데이터 분석기사 #빅분기실기 #데이터마님 # 빅분기실기준비
- tersorboard mapping
- OPIC 당일치기
- 음성전처리 #음성처리 #python 음성추출 # python 음성 추출 #moviepy
- OPIC 오늘 시작
- 강화학습 간단 정리
- DDPG
- ImportError: cannot import name 'Mapping' from 'collections' tensrorbaord
- 일기 #다짐
- tesorboard
- tensorboard 에러
- whisper jax
- dice loss
- reinforced learning
- 공개키 docker
- OPIC 번개
- OPIC 하루전 시작
- ImportError: cannot import name 'Mapping' from 'collections'
- gpt excel 사용
- ollama
- tensorboard html5
- docker 환경 문제
- 인간종말
- OPIC 시험 전날
- focal loss
- OPIC 하루 전
- AI모델
- cross entoropy
- AI생성함
- Today
- Total
Moonie
[빅데이터 분석기사 실기] 데이터 전처리 python 100 - 8 본문
아래 블로그를 참고하여 진행했습니다.
https://www.datamanim.com/dataset/99_pandas/pandasMain.html#google_vignette
이전 블로그에 이어서 작성했습니다.
[빅데이터 분석기사 실기] 데이터 전처리 python 100 - 4
아래 블로그를 참조해서 진행했습니다.https://www.datamanim.com/dataset/99_pandas/pandasMain.html 해당 글에 이어서 진행한다.https://moonie.tistory.com/34 [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 3
moonie.tistory.com
06_Pivot
데이터
국가별 5세이하 사망비율 통계 : https://www.kaggle.com/utkarshxy/who-worldhealth-statistics-2020-complete
Dataurl = ‘https://raw.githubusercontent.com/Datamanim/pandas/main/under5MortalityRate.csv’
데이터 호출
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/Datamanim/pandas/main/under5MortalityRate.csv')

Question 83
Indicator을 삭제하고 First Tooltip 컬럼에서 신뢰구간에 해당하는 표현을 지워라
1) Indicator를 삭제
df.drop('Indicator',axis=1,inplace=True)
df.head(3)
- df.drop을 통해서 열을 제거
- axis=1: 제거할 방향을 지정하는 매개변수로, axis=1은 열을 의미합니다 (axis=0은 행을 의미합니다).
- inplace=True: 원본 데이터프레임 df를 수정하여 'Indicator' 열을 제거하도록 설정합니다. inplace=True를 지정하지 않으면, 열이 제거된 새로운 데이터프레임이 반환됩니다
2) First Tooltip신뢰구간에 해당하는 표현 삭제
.
df['First Tooltip'] = df['Fisrst Tooltip'].map(lambda x: float(x.split("[")[0]))
df.head(4)
- df['First Tooltip']: 'First Tooltip'이라는 열을 선택합니다.
- .map(lambda x: ...): map 함수와 람다 함수를 사용하여 'First Tooltip' 열의 각 값에 함수를 적용합니다.
- lambda x: float(x.split("[")[0]): 람다 함수는 x 값을 입력받아, 대괄호 [를 기준으로 문자열을 나눈 후 첫 번째 부분만 선택합니다 (x.split("[")[0]). 이후, 이 문자열 부분을 float()로 변환하여 실수형으로 만듭니다.
Question 84
년도가 2015년 이상, Dim1이 Both sexes인 케이스만 추출하라
ans = df[(df.Period>2015) & (df.Dim1 == 'Both sexes')]
ans
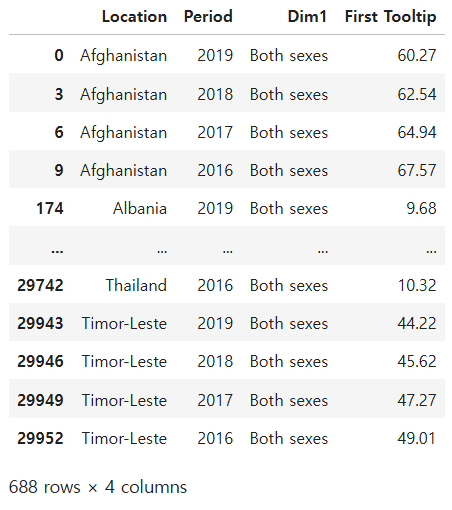
Question 85
84번 문제에서 추출한 데이터로 아래와 같이 나라에 따른 년도별 사망률을 데이터 프레임화 하라
target = ans
ans = target.pivot(index='Location',columns = 'Period', values = 'First Tooltip')
ans.head(3)
- pivot 함수는 데이터의 열을 기준으로 피벗테이블로 변환시키는 메서드 입니다.
- index='Location': 피벗 테이블의 행 레이블을 지정합니다. 여기서는 'Location' 열의 고유 값들이 행이 됩니다.
- columns='Period': 피벗 테이블의 열 레이블을 지정합니다. 여기서는 'Period' 열의 고유 값들이 열이 됩니다.
- values='First Tooltip': 테이블의 값으로 사용할 열을 지정합니다. 'First Tooltip' 열의 값이 새롭게 정의된 행과 열의 위치에 맞게 채워집니다.
Question 86
Dim1에 따른 년도별 사망비율의 평균을 구하라
ans = df.pivot_table(index='Dim1',columns='Period',values='First Tooltip',aggfunc='mean')
ans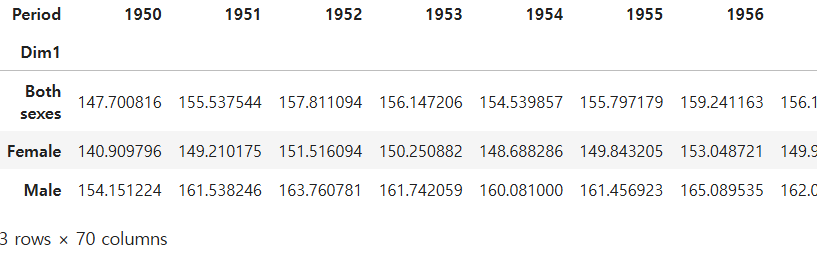
- index='Dim1': 피벗 테이블의 행 레이블을 지정합니다. 'Dim1' 열의 고유 값들이 행으로 설정됩니다.
- columns='Period': 피벗 테이블의 열 레이블을 지정합니다. 'Period' 열의 고유 값들이 열로 설정됩니다.
- values='First Tooltip': 테이블에서 사용할 값의 열을 지정합니다. 'First Tooltip' 열의 값을 각 위치에 넣습니다.
- aggfunc='mean': 피벗 테이블의 집계 함수를 지정합니다. 'First Tooltip' 열의 값이 여러 개일 경우, 그 값들의 평균(mean)을 계산하여 셀을 채웁니다.
올림픽 메달리스트 정보 데이터: https://www.kaggle.com/the-guardian/olympic-games
dataUrl =’https://raw.githubusercontent.com/Datamanim/pandas/main/winter.csv’
Question 87
데이터에서 한국 KOR 데이터만 추출하라
ans = df[df.Country == 'KOR']
ans.head(5)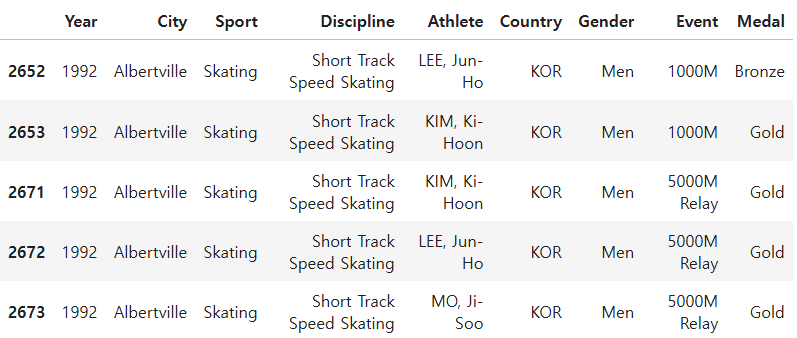
Question 88
한국 올림픽 메달리스트 데이터에서 년도에 따른 medal 갯수를 데이터프레임화 하라
kr = df[df.Country == 'KOR']
ans = kr.pivot_talbe(index='Year',columns='Medal',aggfunc='size).fillna(0)
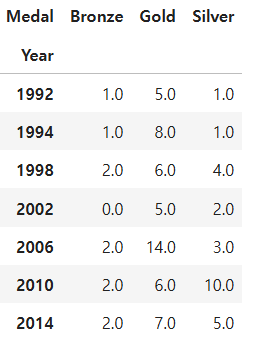
Question 89
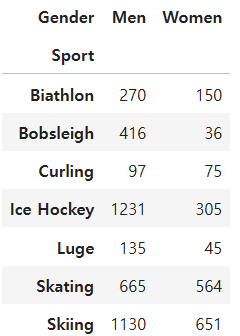
전체 데이터에서 sport종류에 따른 성별수를 구하여라
ans = df.pivot_table(index='Sport',columns='Gender',aggfunc='size')
ans
Question 90
전체 데이터에서 Discipline종류에 따른 따른 Medal수를 구하여라
Ans = df.pivot_table(index='Discipline',columns='Medal',aggfunc='size')

07_Merge , Concat
국가별 5세이하 사망비율 통계 : https://www.kaggle.com/utkarshxy/who-worldhealth-statistics-2020-complete
데이터 변형
Dataurl = ‘https://raw.githubusercontent.com/Datamanim/pandas/main/mergeTEst.csv’
데이터 호출
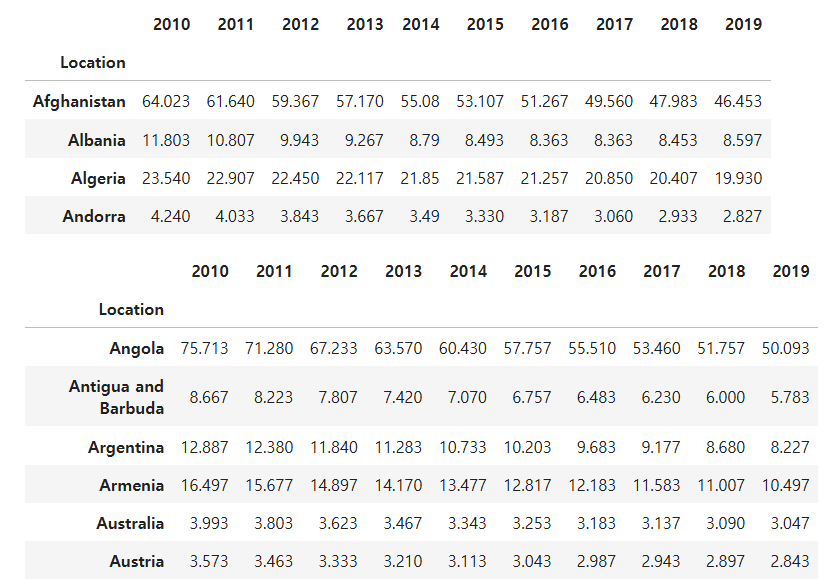
df = pd.read_csv('https://raw.githubusercontent.com/Datamanim/pandas/main/mergeTEst.csv',index_col=0)
df1 = df.iloc[:4,:]
df2 = df.iloc[4:,:]
display(df1)
display(df2)
Question 91
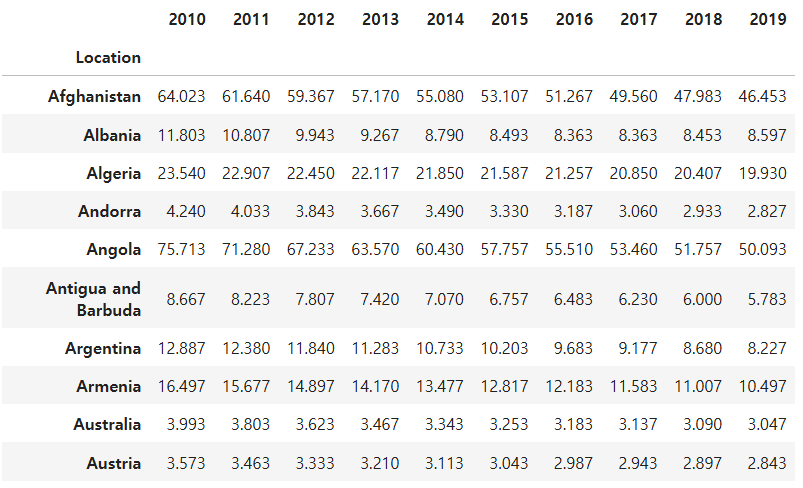
df1과 df2 데이터를 하나의 데이터 프레임으로 합쳐라
total = pd.concat([df1,df2])
ans = total
ans
Question 92
df3 = df.iloc[:2,:4]
df4 = df.iloc[5:,3:]
display(df3)
display(df4)
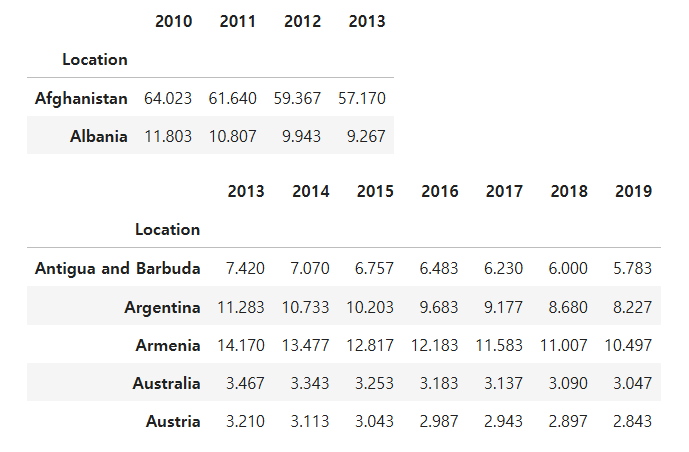
df3과 df4 데이터를 하나의 데이터 프레임으로 합쳐라. 둘다 포함하고 있는 년도에 대해서만 고려한다
Ans = pd.concat([df3,df4],join='inner')
Ans
join='inner': 결합할 때의 조인 방식을 지정합니다. inner 조인은 두 데이터프레임에 공통으로 있는 열만 결합에 사용하므로, 서로 다른 열이 있으면 제외됩니다.
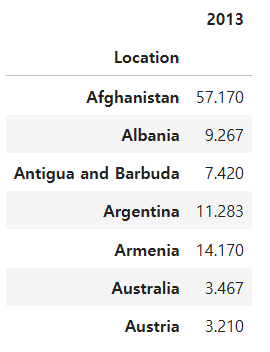
Question 93
df3과 df4 데이터를 하나의 데이터 프레임으로 합쳐라. 모든 컬럼을 포함하고, 결측치는 0으로 대체한다
Ans = pd.concat([df3,df4]).fillna(0)
Ans
Question 94
df5 = df.T.iloc[:7,:3]
df6 = df.T.iloc[6:,2:5]
display(df5)
display(df6)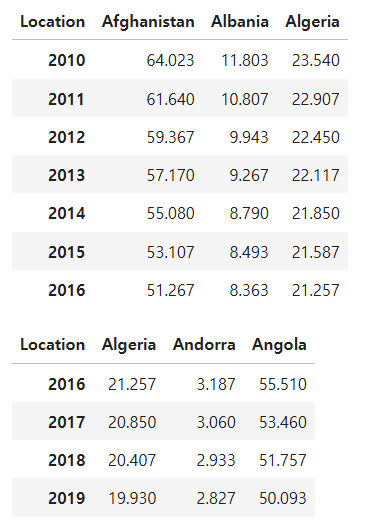
df5과 df6 데이터를 하나의 데이터 프레임으로 merge함수를 이용하여 합쳐라. Algeria컬럼을 key로 하고 두 데이터 모두 포함하는 데이터만 출력하라
Ans = pd.merge(df5,df6,on='Algeria',how='inner')
Ans
Question 95
df5과 df6 데이터를 하나의 데이터 프레임으로 merge함수를 이용하여 합쳐라. Algeria컬럼을 key로 하고 합집합으로 합쳐라
Ans =pd.merge(df5,df6,on='Algeria',how='outer')
Ans
- on='Algeria': 병합 기준이 되는 열입니다. 두 데이터프레임 모두에 'Algeria'라는 열이 있어야 하며, 이 열의 값을 기준으로 데이터를 병합합니다.
- how='outer': 병합 방식으로, outer 조인을 의미합니다. outer 조인은 두 데이터프레임의 'Algeria' 열의 모든 값을 포함하며, 일치하지 않는 값에 대해서는 NaN을 채웁니다.
이로써 홈페이지에 있는 모든 예제를 실행해 보았다. 아직 손에 익지 않아 어려움이 있지만
시험까지 다른 실습 문제들로손에 익을 때 까지 연습해야겠다.
'공부 > 자격증' 카테고리의 다른 글
| [빅데이터 분석기사 실기] 작업 1유형 - 2 (4) | 2024.10.29 |
|---|---|
| [빅데이터 분석기사 실기] 작업 1유형 - 1 (3) | 2024.10.28 |
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 7 (3) | 2024.10.26 |
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 6 (5) | 2024.10.22 |
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 5 (0) | 2024.10.22 |



