
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 공개키 docker
- tersorboard mapping
- 인간종말
- ollama
- OPIC 시험 전날
- DDPG
- tensorboard html5
- 일기 #다짐
- whisper jax
- ImportError: cannot import name 'Mapping' from 'collections'
- 음성전처리 #음성처리 #python 음성추출 # python 음성 추출 #moviepy
- docker 환경 문제
- OPIC 하루 전
- reinforced learning
- OPIC 오늘 시작
- gpt excel 사용
- dice loss
- tesorboard
- ImportError: cannot import name 'Mapping' from 'collections' tensrorbaord
- 엑셀에 ollama
- OPIC 당일치기
- 빅데이터 분석기사 #빅분기실기 #데이터마님 # 빅분기실기준비
- focal loss
- AI생성함
- cross entoropy
- AI모델
- 강화학습 간단 정리
- tensorboard 에러
- OPIC 하루전 시작
- OPIC 번개
- Today
- Total
Moonie
[빅데이터 분석기사 실기] 데이터 전처리 python 100 - 7 본문
아래 블로그를 참고하여 진행했습니다.
https://www.datamanim.com/dataset/99_pandas/pandasMain.html#google_vignette
이전 블로그에 이어서 작성했습니다.
데이터를 호출합니다.
import pandas as pd
dataurl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/seoul_pm.csv'
df =pd.read_csv(dataurl)
Question 76
년-월-일:시 컬럼을 pandas에서 인식할 수 있는 datetime 형태로 변경하라. 서울시의 제공데이터의 경우 0시가 24시로 표현된다
def change_date(x):
import datetime
hour = x.split(':')[1]
date = x.split(':')[0]
if hour =='24':
hour='00:00:00'
FinalDate = pd.to_datetime(date+" "+hour) +datetime.timedelta(days=1)
else:
hour = hour + ':00:00'
FinalDate = pd.to_datetime(date+" "+hour)
return FinalDate
df['(년-월-일:시)'] = df['(년-월-일:시)'].apply(change_date)
Ans = df
Ans.head(3)
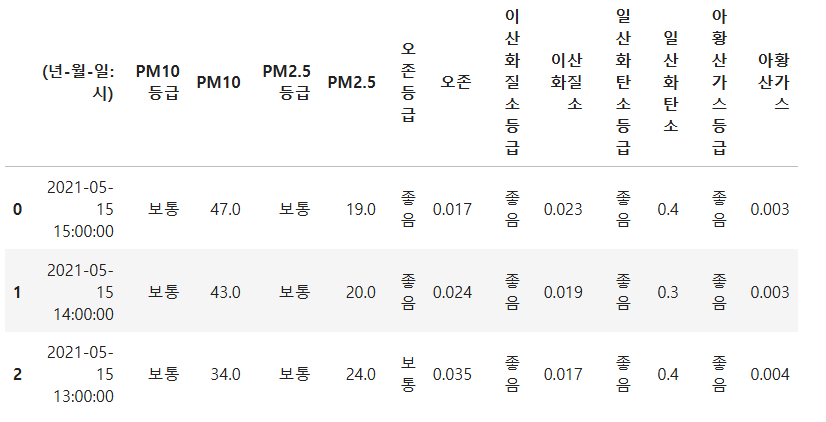
datetime.timedelta를 통해서 시간을 더하고 뺄 수 있음
Question 77
일자별 영어요일 이름을 dayName 컬럼에 저장하라
df['dayName'] =df['(년-월-일:시)'].dt.day_name()
Ans =df['dayName']
Ans.head(5)

dt.day_name() 을 통해서 영어요일 이름으로 저장
Question 78
일자별 각 PM10등급의 빈도수를 파악하라
ans1 = df.groupby(['dayName','PM10등급'],as_index=False).size()
ans1.head()

size()는 각 그룹의 원소 개수를 세어 데이터프레임으로 반환하는 역할을 합니다.
ans2 = ans1.pivot(index='dayName',columns='PM10등급',values='size').fillna(0)
ans2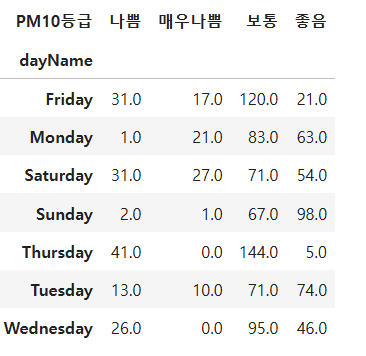
- .pivot() 메서드는 ans1을 dayName을 인덱스로, PM10등급을 열로 가지는 형태의 피벗 테이블로 변환합니다.
- values='size'를 사용하여 각 dayName과 PM10등급 조합에 해당하는 개수를 값으로 설정합니다.
- .fillna(0)는 데이터가 없는 경우 결측값(NaN)을 0으로 채워 요일별로 모든 PM10 등급의 개수를 표시할 수 있게 합니다.
Question 79
시간이 연속적으로 존재하며 결측치가 없는지 확인하라
check = len(df['(년-월-일:시)'].diff().unique())
if check == 2:
Ans =True
else:
Ans =False

df['(년-월-일:시)'].diff() 를 하면 한가지 값 밖에 나오지 않음으로 True가 나온다.
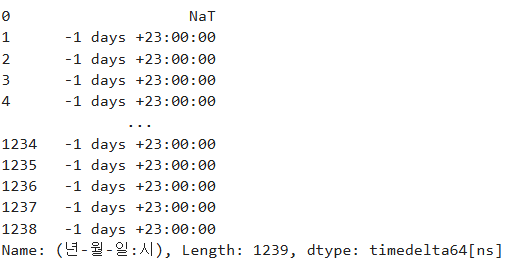
Question 80
오전 10시와 오후 10시(22시)의 PM10의 평균값을 각각 구하여라
기존 글 그대로 사용하면 에러가 나게된다. mean() 함수가 문자열 등 숫자가 아닌 데이터를 처리할 수 없어 에러가 발생하였다. 수정하면 다음과 같이 입력해야 한다.
Ans = df.select_dtypes(include=['number']).groupby(df['(년-월-일:시)'].dt.hour).mean().iloc[[10, 22], [0]]
Ans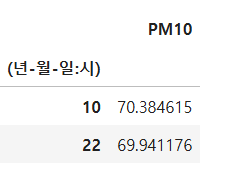
select_dtypes(include=['number']) 를 사용해 숫자형 열만 선택하여 그룹화하고 평균을 계산합니다.
Question 81
날짜 컬럼을 index로 만들어라
df.set_index('(년-월-일:시)',inplace=True,drop=True)
Ans = df
Ans.head(3)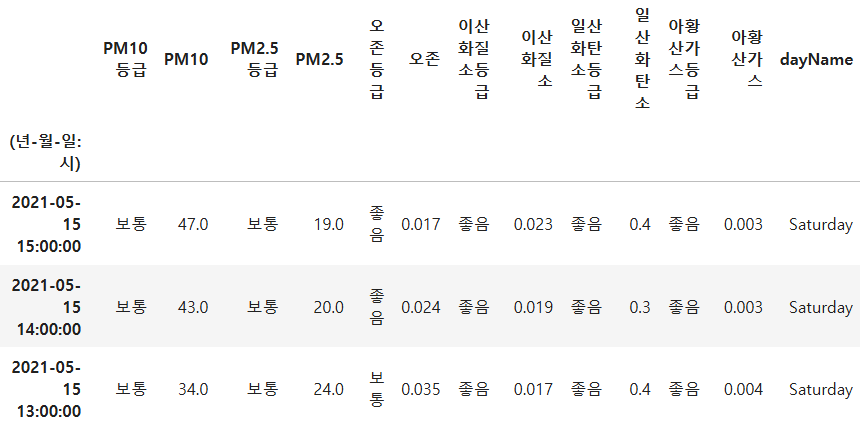
- set_index('(년-월-일:시)'):
- (년-월-일:시)라는 열을 인덱스로 설정하여 데이터프레임을 재구성합니다.
- 이 열은 이제 행을 구분하는 기준(인덱스)이 됩니다.
- inplace=True:
- 이 매개변수를 True로 설정하면 df 데이터프레임이 직접 수정됩니다.
- 새로 생성된 데이터프레임을 반환하지 않고, df 자체가 인덱스를 설정한 상태로 변경됩니다.
- drop=True:
- (년-월-일:시) 열을 데이터프레임에서 제거합니다.
- 인덱스로 지정한 후 이 열이 데이터에 그대로 남아 있지 않도록 합니다.
Question 82
데이터를 주단위로 뽑아서 최소,최대 평균, 표준표차를 구하여라
Ans = df.select_dtypes(include=['number']).resample('W').agg(['min', 'max', 'mean', 'std'])
Ans.head(5)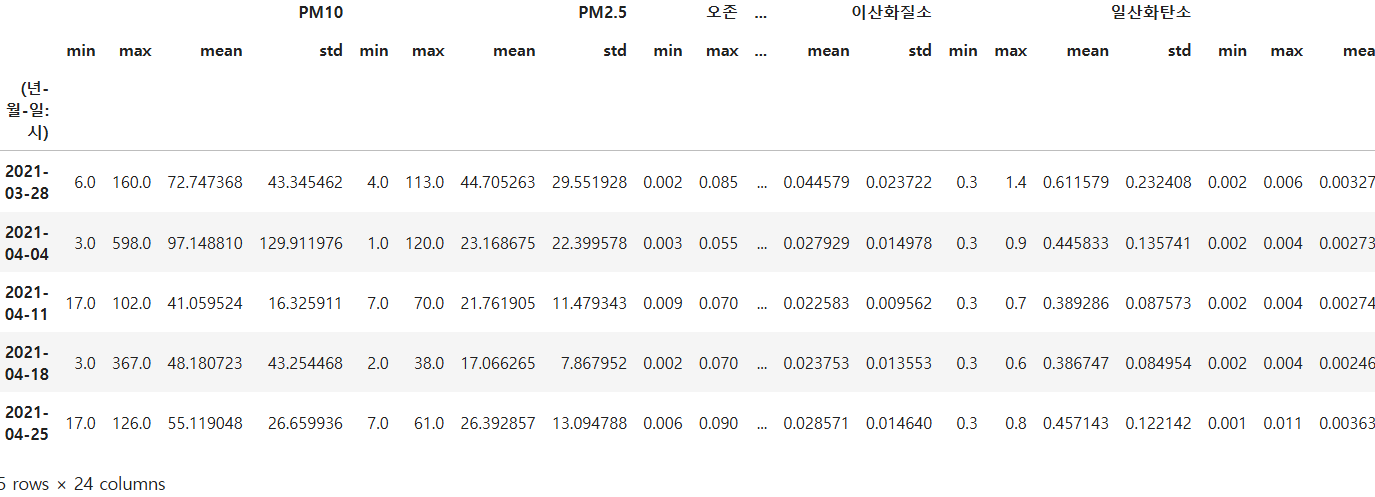
집계 함수는 숫자형 데이터에서만 작동하기 때문에, df에 숫자형이 아닌 열이 포함되어 있으면 오류가 발생합니다.
숫자형 열만 선택하여 집계를 수행하면 이 문제를 해결할 수 있습니다. 다음과 같이 select_dtypes()를 사용해 숫자형 데이터만 포함된 데이터프레임을 대상으로 집계할 수 있습니다.
'공부 > 자격증' 카테고리의 다른 글
| [빅데이터 분석기사 실기] 작업 1유형 - 1 (3) | 2024.10.28 |
|---|---|
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 8 (3) | 2024.10.26 |
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 6 (5) | 2024.10.22 |
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 5 (0) | 2024.10.22 |
| [빅데이터 분석기사 실기] 데이터 전처리 python 100 - 3 (0) | 2024.10.15 |



