[빅데이터 분석기사 실기] 작업 1유형 - 2
데이터마님 블로글 참조하여 실습 했습니다.
https://www.datamanim.com/dataset/03_dataq/typeone.html
작업 1유형 — DataManim
작업 1유형 9회 빅분기 실기 대비 강의, 블로그만으로는 도저히 안되겠다ㅠ 하시는분들에게 추천합니다. 본격적으로 시작하시기 전에 웹광고 한번 눌러주세요 문제 풀이 영상 : https://www.youtube.co
www.datamanim.com
아래 글에 이어서 작성했습니다.
https://moonie.tistory.com/41#google_vignette
[빅데이터 분석기사 실기] 작업 1유형 - 1
데이터마님 블로글 참조하여 실습 했습니다.https://www.datamanim.com/dataset/03_dataq/typeone.html 작업 1유형 — DataManim작업 1유형 9회 빅분기 실기 대비 강의, 블로그만으로는 도저히 안되겠다ㅠ 하시는분
moonie.tistory.com
사용 데이터
데이터 출처 :https://www.kaggle.com/kukuroo3/youtube-episodic-contents-kr(참고, 데이터 수정)
데이터 설명 : 유튜브 “공범” 컨텐츠 동영상 정보 ( 10분 간격 수집)
dataurl1 (비디오 정보) = https://raw.githubusercontent.com/Datamanim/datarepo/main/youtube/videoInfo.csv
dataurl2 (참가자 채널 정보)= https://raw.githubusercontent.com/Datamanim/datarepo/main/youtube/channelInfo.csv
channel =pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/youtube/channelInfo.csv')
video =pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/youtube/videoInfo.csv')
display(channel.head())
display(video.head())
Question 11
각 데이터의 ‘ct’컬럼을 시간으로 인식할수 있게 datatype을 변경하고 video 데이터의 videoname의 각 value 마다 몇개의 데이터씩 가지고 있는지 확인하라
1. ct 컬럼을 시간으로 인식할 수 있게 datatype변경
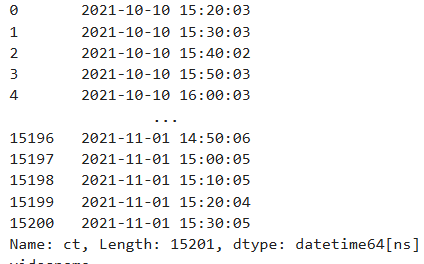
video['ct'] = pd.to_datetime(video['ct'])
print(video['ct'])
2. video 데이터의 videoname의 각 value 마다 몇개의 데이터씩 가지고 있는지확인
answer = video.videoname.value_counts()
print(answer)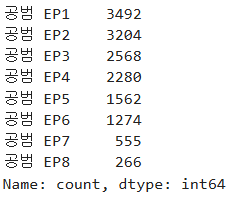
Question 12
수집된 각 video의 가장 최신화 된 날짜의 viewcount값을 출력하라
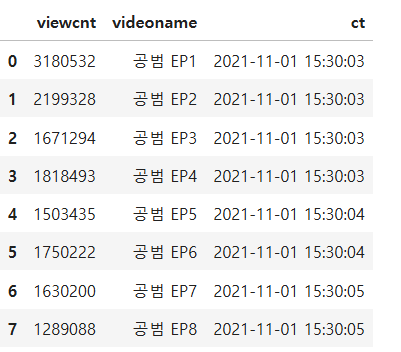
answer = video.sort_values(['videoname','ct']).drop_duplicates('videoname',keep='last')[['viewcnt','videoname','ct']].reset_index(drop=True)
display(answer)
- video.sort_values(['videoname', 'ct']):
- video 데이터프레임을 videoname과 ct 열을 기준으로 정렬합니다.
- videoname별로 그룹화한 후, ct를 기준으로 오름차순으로 정렬합니다. 이로 인해 각 비디오 이름(videoname)별로 가장 오래된 데이터가 먼저 나오고, 가장 최신 데이터가 마지막에 위치하게 됩니다.
- .drop_duplicates('videoname', keep='last'):
- videoname 열을 기준으로 중복된 행을 제거합니다.
- keep='last' 옵션을 사용하여 각 비디오별로 가장 최근(ct 기준) 데이터만 남깁니다.
- [['viewcnt', 'videoname', 'ct']]:
- 정제된 데이터에서 viewcnt, videoname, ct 열만 선택합니다.
- .reset_index(drop=True):
- 기존의 인덱스를 제거하고, 0부터 시작하는 새로운 인덱스를 할당합니다.
- drop=True는 기존 인덱스를 버리고 새 인덱스를 할당하는 옵션입니다.
Question 13
Channel 데이터중 2021-10-03일 이후 각 채널의 처음 기록 됐던 구독자 수(subcnt)를 출력하라
channel.ct = pd.to_datetime(channel.ct)
target = channel[channel.ct >= pd.to_datetime('2021-10-03')].sort_values(['ct','channelname']).drop_duplicates('channelname')
answer = target[['channelname','subcnt']].reset_index(drop=True)
print(answer)
- channel.ct = pd.to_datetime(channel.ct):
- channel 데이터프레임의 ct 열을 날짜 형식으로 변환합니다. 이로 인해 ct 열의 값들이 날짜/시간 데이터로 처리되어 이후 날짜 기준 필터링이 가능합니다.
- channel[channel.ct >= pd.to_datetime('2021-10-03')]:
- ct 열에서 2021년 10월 3일 이후의 데이터만 필터링합니다.
- pd.to_datetime('2021-10-03')을 통해 기준 날짜를 설정하고, channel.ct >= 조건을 사용하여 해당 날짜 이후의 데이터를 선택합니다.
- .sort_values(['ct', 'channelname']):
- 필터링된 데이터를 ct 열과 channelname 열을 기준으로 정렬합니다.
- 먼저 ct를 기준으로 오름차순으로 정렬하고, 동일한 날짜가 있을 경우 channelname으로 정렬하여 일정한 순서를 유지합니다.
- .drop_duplicates('channelname'):
- channelname 열을 기준으로 중복된 행을 제거합니다.
- 각 채널별로 중복된 행이 있는 경우, 가장 처음 등장하는 행만 남기고 나머지를 제거합니다.
- target[['channelname', 'subcnt']]:
- 중복 제거 후, channelname과 subcnt 열만 선택합니다. target 데이터프레임에는 이 두 열만 남게 됩니다.
- .reset_index(drop=True):
- 기존 인덱스를 제거하고, 0부터 시작하는 새로운 인덱스를 할당합니다.
- drop=True는 기존 인덱스를 버리고 새 인덱스를 할당하는 옵션입니다.
Question 14
각채널의 2021-10-03 03:00:00 ~ 2021-11-01 15:00:00 까지 구독자수 (subcnt) 의 증가량을 구하여라
end = channel.loc[channel.ct.dt.strftime('%Y-%m-%d %H') =='2021-11-01 15']
start = channel.loc[channel.ct.dt.strftime('%Y-%m-%d %H') =='2021-10-03 03']
end_df = end[['channelname','subcnt']].reset_index(drop=True)
start_df = start[['channelname','subcnt']].reset_index(drop=True)
end_df.columns = ['channelname','end_sub']
start_df.columns = ['channelname','start_sub']
tt = pd.merge(start_df,end_df)
tt['del'] = tt['end_sub'] - tt['start_sub']
result = tt[['channelname','del']]
display(result)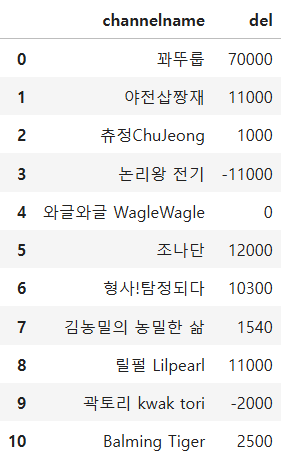
- end = channel.loc[channel.ct.dt.strftime('%Y-%m-%d %H') == '2021-11-01 15']:
- channel.ct.dt.strftime('%Y-%m-%d %H')는 ct 열의 날짜와 시간을 "YYYY-MM-DD HH" 형식의 문자열로 변환합니다.
- 이 조건을 통해 2021-11-01 15 (2021년 11월 1일 오후 3시)의 데이터를 필터링하여 end 데이터프레임에 저장합니다.
- start = channel.loc[channel.ct.dt.strftime('%Y-%m-%d %H') == '2021-10-03 03']:
- 비슷한 방식으로 2021-10-03 03 (2021년 10월 3일 오전 3시)의 데이터를 필터링하여 start 데이터프레임에 저장합니다.
- end_df = end[['channelname', 'subcnt']].reset_index(drop=True) 및 start_df = start[['channelname', 'subcnt']].reset_index(drop=True):
- end와 start 데이터프레임에서 channelname과 subcnt 열만 선택하고, 인덱스를 리셋합니다.
- 이로 인해 각 데이터프레임은 해당 시점의 구독자 수(subcnt)를 포함한 채널별 정보만 남게 됩니다.
- end_df.columns = ['channelname', 'end_sub'] 및 start_df.columns = ['channelname', 'start_sub']:
- end_df와 start_df의 열 이름을 각각 end_sub와 start_sub로 변경합니다.
- 이렇게 하면 이후 병합 및 계산 시 end와 start 시점의 구독자 수를 구분할 수 있게 됩니다.
- tt = pd.merge(start_df, end_df):
- start_df와 end_df를 channelname을 기준으로 병합합니다.
- 병합된 결과 tt 데이터프레임에는 각 채널의 시작 구독자 수(start_sub)와 종료 구독자 수(end_sub)가 나란히 존재하게 됩니다.
- tt['del'] = tt['end_sub'] - tt['start_sub']:
- end_sub와 start_sub의 차이를 계산하여 del 열에 저장합니다.
- 이 값은 주어진 기간 동안 각 채널의 구독자 수 변화(증감량)를 나타냅니다.
- result = tt[['channelname', 'del']]:
- channelname과 del 열만 선택하여 최종 결과 데이터프레임인 result를 생성합니다.
Question 15
각 비디오는 10분 간격으로 구독자수, 좋아요, 싫어요수, 댓글수가 수집된것으로 알려졌다. 공범 EP1의 비디오정보 데이터중 수집간격이 5분 이하, 20분이상인 데이터 구간( 해당 시점 전,후) 의 시각을 모두 출력하라
import datetime
ep_one = video.loc[video.videoname.str.contains('1')].sort_values('ct').reset_index(drop=True)
ep_one[
(ep_one.ct.diff(1) >=datetime.timedelta(minutes=20)) | \
(ep_one.ct.diff(1) <=datetime.timedelta(minutes=5))
]
answer = ep_one[ep_one.index.isin([720,721,722,723,1635,1636,1637])]
display(answer)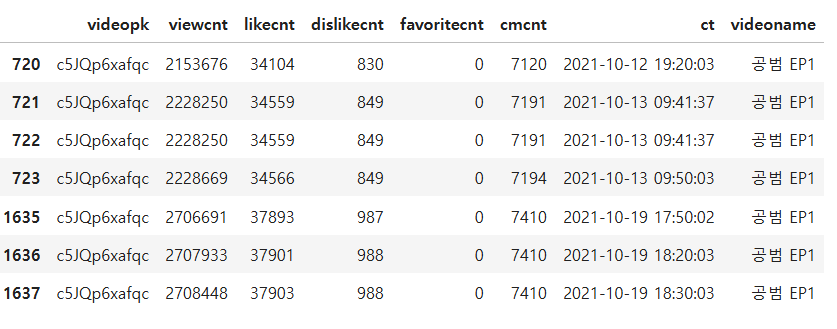
ep_one = video.loc[video.videoname.str.contains('1')].sort_values('ct').reset_index(drop=True)
-
- video 데이터프레임에서 videoname 열에 '1'이 포함된 행들만 필터링합니다. 이는 1화와 관련된 비디오들을 찾기 위함입니다.
- 필터링된 결과는 ct 열(아마도 날짜나 시간 정보가 포함된 열) 기준으로 정렬하고, 인덱스를 리셋하여 ep_one 데이터프레임에 저장합니다.
ep_one[
(ep_one.ct.diff(1) >= datetime.timedelta(minutes=20)) | \
(ep_one.ct.diff(1) <= datetime.timedelta(minutes=5))
]
- ep_one.ct.diff(1)은 ct 열의 시간 차이를 계산하는데, 각 행의 시간과 그 이전 행의 시간의 차이를 나타냅니다.
- 이 조건문은 시간 차이가 20분 이상 또는 5분 이하인 행을 필터링합니다.
answer = ep_one[ep_one.index.isin([720,721,722,723,1635,1636,1637])]
- 덱스가 [720, 721, 722, 723, 1635, 1636, 1637]인 행들을 ep_one에서 선택하여 answer에 저장합니다.
- 이 단계는 특정 행들만을 필요로 할 때 사용됩니다.
Question 16
각 에피소드의 시작날짜(년-월-일)를 에피소드 이름과 묶어 데이터 프레임으로 만들고 출력하라
start_date = video.sort_values(['ct','videoname']).drop_duplicates('videoname')[['ct','videoname']]
start_date['date'] = start_date.ct.dt.date
answer = start_date[['date','videoname']]
display(answer)

start_date = video.sort_values(['ct', 'videoname']).drop_duplicates('videoname')[['ct', 'videoname']]
- video 데이터프레임에서 ct(아마도 비디오의 생성 또는 업로드 시간)와 videoname 열을 기준으로 데이터를 정렬합니다. ct를 기준으로 먼저 정렬하고, 같은 ct 내에서는 videoname에 따라 정렬합니다.
- 각 비디오 이름별로 첫 번째로 등장하는 행만 남기기 위해 drop_duplicates('videoname')을 사용합니다. 즉, 각 비디오 이름별로 최초의 시간 정보를 가져옵니다.
start_date['date'] = start_date.ct.dt.date
- ct 열에서 날짜만 추출하여 새로운 열인 date에 저장합니다.
- ct가 datetime 형식이라면 dt.date를 통해 시간 정보 없이 날짜만 가져올 수 있습니다. 이를 통해 각 비디오가 최초로 등장한 날짜만을 기록하게 됩니다.
Question 17
“공범” 컨텐츠의 경우 19:00시에 공개 되는것으로 알려져있다. 공개된 날의 21시의 viewcnt, ct, videoname 으로 구성된 데이터 프레임을 viewcnt를 내림차순으로 정렬하여 출력하라
video['time']= video.ct.dt.hour
answer = video.loc[video['time'] ==21] \
.sort_values(['videoname','ct'])\
.drop_duplicates('videoname') \
.sort_values('viewcnt',ascending=False)[['videoname','viewcnt','ct']]\
.reset_index(drop=True)
display(answer)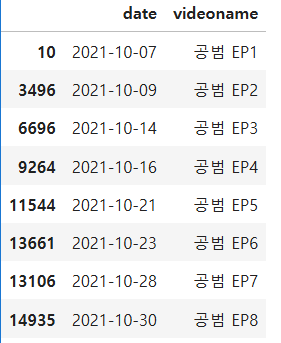
video['time'] = video.ct.dt.hour
ct 열에서 시간(hour) 부분만 추출하여 time 열에 저장합니다.
video.loc[video['time'] == 21]time 열이 21인(즉, 오후 9시에 업로드된) 비디오만 필터링합니다.
.sort_values(['videoname', 'ct']).drop_duplicates('videoname')먼저, videoname과 ct를 기준으로 데이터를 정렬합니다.
videoname으로 정렬된 상태에서 각 비디오 이름의 가장 첫 번째(가장 오래된) 업로드만 남기기 위해 drop_duplicates('videoname')을 사용하여 중복을 제거합니다.
.sort_values('viewcnt', ascending=False)[['videoname', 'viewcnt', 'ct']]
- 조회수(viewcnt)를 기준으로 내림차순으로 정렬하여, 조회수가 높은 순서대로 비디오를 나열합니다.
- 결과로 videoname, viewcnt, ct 열만 선택합니다.
.reset_index(drop=True)
display(answer)인덱스를 리셋하여 깔끔하게 answer 데이터프레임에 저장하고 출력합니다.
Question 18
video 정보의 가장 최근 데이터들에서 각 에피소드의 싫어요/좋아요 비율을 ratio 컬럼으로 만들고 videoname, ratio로 구성된 데이터 프레임을 ratio를 오름차순으로 정렬하라
# 1. 최근 데이터 정렬
target = video.sort_values('ct').drop_duplicates('videoname',keep='last')
# 2. 각 에피소드의 싫어요/좋아요 비율을 ratio 컬럼으로
target['ratio'] = target['dislikecnt']/target['likecnt']
# 3. videoname, ratio 로 구성된 데이터 프레임을 ratio를 오름차순으로 정렬
answer = target.sort_values('ratio')[['videoname','ratio']].reset_index(drop=True)
answer
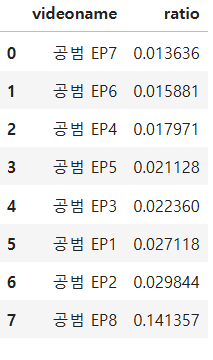
target = video.sort_values('ct').drop_duplicates('videoname', keep='last')
- ct(날짜 또는 시간 열) 기준으로 데이터를 정렬하여 최신 데이터가 뒤에 위치하도록 합니다.
- drop_duplicates('videoname', keep='last')를 사용하여 videoname 별로 중복을 제거하고, 가장 마지막 데이터(즉, 가장 최근 데이터)만 남깁니다.
- 이렇게 해서 각 비디오 이름별로 최신 데이터를 포함하는 target 데이터프레임이 생성됩니다.
target['ratio'] = target['dislikecnt'] / target['likecnt']
- dislikecnt(싫어요 수)와 likecnt(좋아요 수)를 사용하여 ratio 열에 싫어요와 좋아요 비율을 계산합니다.
answer = target.sort_values('ratio')[['videoname', 'ratio']].reset_index(drop=True)
- ratio 열을 기준으로 오름차순 정렬하여, 싫어요 비율이 낮은 비디오부터 높은 비디오 순으로 정렬합니다.
- 최종적으로 videoname과 ratio 열만 선택하여 answer에 저장하고, 인덱스를 리셋합니다.
Question 19
2021-11-01 00:00:00 ~ 15:00:00까지 각 에피소드별 viewcnt의 증가량을 데이터 프레임으로 만드시오
start = pd.to_datetime("2021-11-01 00:00:00")
end = pd.to_datetime("2021-11-01 15:00:00")
target = video.loc[(video["ct"] >= start) & (video['ct'] <= end)].reset_index(drop=True)
def check(x):
result = max(x) - min(x)
return result
answer = target[['videoname','viewcnt']].groupby("videoname").agg(check)
answer

start = pd.to_datetime("2021-11-01 00:00:00")
end = pd.to_datetime("2021-11-01 15:00:00")- start와 end 변수를 설정하여 특정 시간 범위를 정의합니다. 여기서는 2021년 11월 1일 00:00부터 15:00까지의 데이터를 필터링하려고 합니다.
target = video.loc[(video["ct"] >= start) & (video['ct'] <= end)].reset_index(drop=True)
- video 데이터프레임에서 ct 열이 start와 end 사이에 있는 행만 선택하여 target 데이터프레임에 저장합니다.
- reset_index(drop=True)를 사용해 인덱스를 초기화하여 선택된 데이터에 새 인덱스를 부여합니다.
def check(x):
result = max(x) - min(x)
return result
- check 함수는 입력된 x(조회수 리스트)에서 최대값과 최소값의 차이를 계산하여 변동 값을 반환합니다. 이를 통해 조회수 변동 폭을 구할 수 있습니다.
answer = target[['videoname', 'viewcnt']].groupby("videoname").agg(check)
- videoname을 기준으로 그룹화하고, viewcnt(조회수) 열에 대해 check 함수를 적용하여 각 비디오의 조회수 변동 폭을 계산합니다.
- 결과는 videoname별 조회수 변동을 나타내는 answer 데이터프레임에 저장됩니다.
Question 20
video 데이터 중에서 중복되는 데이터가 존재한다. 중복되는 각 데이터의 시간대와 videoname 을 구하여라
answer = video[video.index.isin(set(video.index) - set(video.drop_duplicates().index))]
result = answer[['videoname','ct']]
display(result)

answer = video[video.index.isin(set(video.index) - set(video.drop_duplicates().index))]
- video.drop_duplicates().index: video 데이터프레임에서 중복된 행을 제거한 후의 인덱스를 반환합니다.
- set(video.index) - set(video.drop_duplicates().index): 원래 인덱스에서 중복되지 않은 인덱스를 빼서 중복된 인덱스만 남깁니다.
- video[video.index.isin(...)]: video 데이터프레임에서 중복된 인덱스를 가진 행들만 선택하여 answer 변수에 저장합니다.
result = answer[['videoname', 'ct']]- answer 데이터프레임에서 videoname과 ct 열만 선택하여 result 변수에 저장합니다.