[빅데이터 분석기사 실기] 데이터 전처리 python 100 - 6
아래 블로그를 참고하여 진행했습니다.
https://www.datamanim.com/dataset/99_pandas/pandasMain.html#google_vignette
이전 블로그에 이어서 작성했습니다.
04_Apply , Map
Question 56 데이터를 로드하고 데이터 행과 열의 갯수를 출력하라
import pandas as pd
dataurl='https://raw.githubusercontent.com/Datamanim/pandas/main/BankChurnersUp.csv'
df = pd.read_csv(dataurl)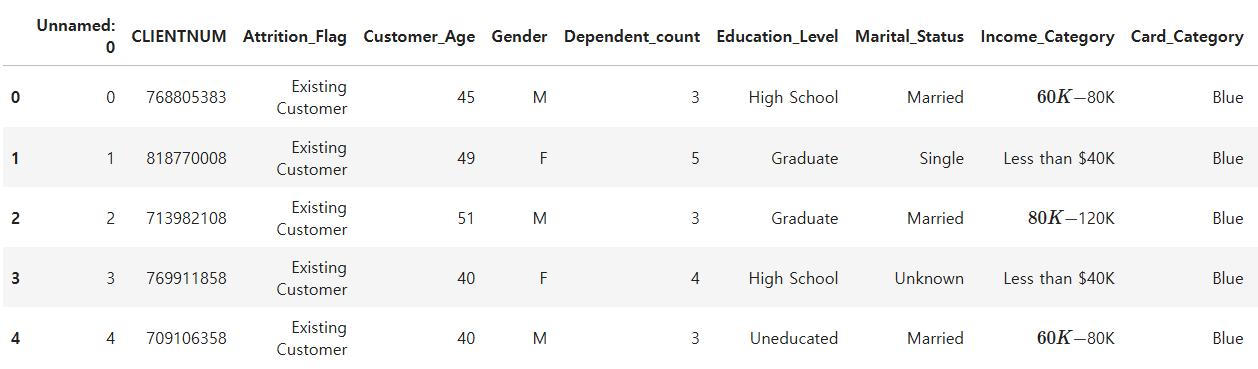
Question 57 Income_Category의 카테고리를 map 함수를 이용하여 다음과 같이 변경하여 newIncome 컬럼에 매핑하라
Unknown : N
Less than $40K : a
$40K - $60K : b
$60K - $80K : c
$80K - $120K : d
$120K +’ : e
dic = {
'Unknown' : 'N',
'Less than $40K' : 'a',
'$40K - $60K' : 'b',
'$60K - $80K' : 'c',
'$80K - $120K' : 'd',
'$120K +' : 'e'
}
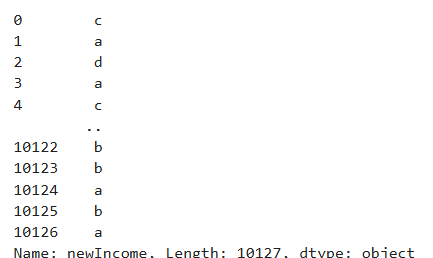
df['newIncome'] =df.Income_Category.map(lambda x: dic[x])
Ans = df['newIncome'].map():
- **.map()**은 Pandas 시리즈(열)에 대해 각 요소를 다른 값으로 변환하는 메서드입니다.
- 이 메서드는 각 요소에 대해 변환 작업을 수행할 때 사전(dictionary) 또는 함수를 사용할 수 있습니다.
- 여기서는 lambda x: dic[x]라는 람다 함수를 사용하여, Income_Category 열의 각 값(x)을 **사전 dic**을 참조하여 변환하고 있습니다.
lambda x: dic[x]:
- 람다 함수는 간단한 익명 함수로, 이 경우 Income_Category의 각 값을 입력받아, 해당 값을 사전 dic에서 찾은 후 반환하는 역할을 합니다.
- 예를 들어, Income_Category에 있는 값이 "Low"라면, dic['Low']를 반환합니다.
- 즉, Income_Category의 각 값은 dic 사전에서 매핑된 값으로 변환됩니다.
Question 58 Income_Category의 카테고리를 apply 함수를 이용하여 다음과 같이 변경하여 newIncome 컬럼에 매핑하라 Unknown : N
Less than $40K : a
$40K - $60K : b
$60K - $80K : c
$80K - $120K : d
$120K +’ : e
apply 함수는 파이썬의 pandas 라이브러리에서 매우 유용하게 사용되는 함수 중 하나로, 데이터프레임의 각 행이나 열에 대해 함수를 적용할 때 사용됩니다.
def changeCategory(x):
if x =='Unknown':
return 'N'
elif x =='Less than $40K':
return 'a'
elif x =='$40K - $60K':
return 'b'
elif x =='$60K - $80K':
return 'c'
elif x =='$80K - $120K':
return 'd'
elif x =='$120K +' :
return 'e'
df['newIncome'] =df.Income_Category.apply(changeCategory)
Ans = df['newIncome']
Question 59 Customer_Age의 값을 이용하여 나이 구간을 AgeState 컬럼으로 정의하라. (0~9 : 0 , 10~19 :10 , 20~29 :20 … 각 구간의 빈도수를 출력하라
df['AgeState'] = df.Customer_Age.map(lambda x:x//10 *10)
Ans = df['AgeState'].value_counts().sort_index()
Ans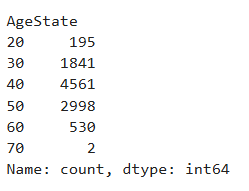
Question 60 Education_Level의 값중 Graduate단어가 포함되는 값은 1 그렇지 않은 경우에는 0으로 변경하여 newEduLevel 컬럼을 정의하고 빈도수를 출력하라
df['newEduLevel'] = df.Education_Level.map(lambda x : 1 if 'Graduate' in x else 0)
Ans = df['newEduLevel'].value_counts()
Ans
Question 61
Credit_Limit 컬럼값이 4500 이상인 경우 1 그외의 경우에는 모두 0으로 하는 newLimit 정의하라. newLimit 각 값들의 빈도수를 출력하라
df['newLimit'] = df.Credit_Limit.map(lambda x : 1 if x>=4500 else 0)
Ans = df['newLimit'].value_counts()
Ans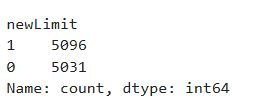
Question 62
Marital_Status 컬럼값이 Married 이고 Card_Category 컬럼의 값이 Platinum인 경우 1 그외의 경우에는 모두 0으로 하는 newState컬럼을 정의하라. newState의 각 값들의 빈도수를 출력하라
def check(x):
if x.Marital_Status == 'Married' and x.Card_Category == 'Platinum' :
return 1
else :
return 0
df['newState'] = df.apply(check,axis=1)
Ans = df['newState'].value_counts()
Ans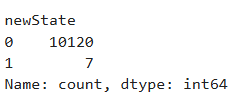
Question 63
Gender 컬럼값 M인 경우 male F인 경우 female로 값을 변경하여 Gender 컬럼에 새롭게 정의하라. 각 value의 빈도를 출력하라
def ChangeGender(x):
if x == 'M':
return 'male'
else :
return 'female'
df['Gender'] = df.Gender.apply(ChangeGender)
Ans = df['Gender'].value_counts()
Ans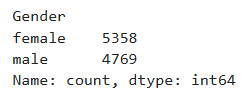
05_Time_Series
Question 64
데이터를 로드하고 각 열의 데이터 타입을 파악하라
import pandas as pd
DataUrl = 'https://raw.githubusercontent.com/Datamanim/pandas/main/timeTest.csv'
df = pd.read_csv(DataUrl)
df.info()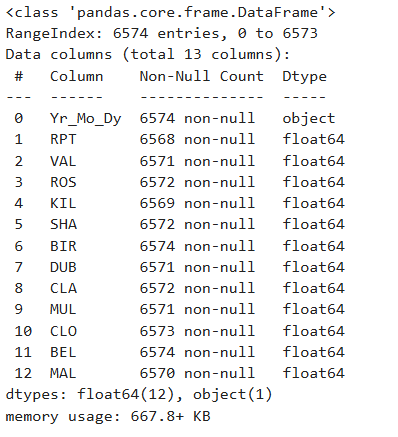
Question 65
Yr_Mo_Dy을 판다스에서 인식할 수 있는 datetime64타입으로 변경하라
df.Yr_Mo_Dy = pd.to_datetime(df.Yr_Mo_Dy)
Ans = df.Yr_Mo_Dy
Ans.head(4)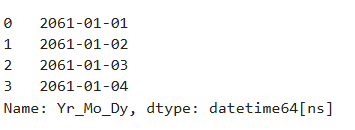
pd.to_datetime() 함수는 pandas의 날짜 처리 함수로, 주어진 데이터를 날짜 형식(datetime)으로 변환해줍니다.
Question 66
Yr_Mo_Dy에 존재하는 년도의 유일값을 모두 출력하라
df.Yr_Mo_Dy.dt.year.unique()
Question 67
Yr_Mo_Dy에 년도가 2061년 이상의 경우에는 모두 잘못된 데이터이다. 해당경우의 값은 100을 빼서 새롭게 날짜를 Yr_Mo_Dy 컬럼에 정의하라
def fix_century(x):
import datetime
year = x.year - 100 if x.year >= 2061 else x.year
return pd.to_datetime(datetime.date(year, x.month, x.day))
df['Yr_Mo_Dy'] = df['Yr_Mo_Dy'].apply(fix_century)
Ans = df.head(4)
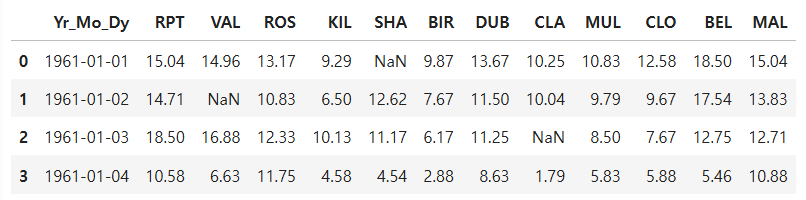
Question 68
년도별 각컬럼의 평균값을 구하여라
ans = df.groupby(df.Yr_Mo_Dy.dt.year).mean()
ans.head(4)

Question 69
weekday컬럼을 만들고 요일별로 매핑하라 ( 월요일: 0 ~ 일요일 :6)
df['weekday'] = df.Yr_Mo_Dy.dt.weekday
Ans = df['weekday'].head(3).to_frame()
Ans
Question 70
weekday컬럼을 기준으로 주말이면 1 평일이면 0의 값을 가지는 WeekCheck 컬럼을 만들어라
df['weekcheck'] = df['weekday'].map(lambda x : 1 if x in [5,6] else 0)
Ans = df['weekcheck'].head(3).to_frame()
Ans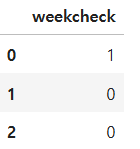
Question 71
년도, 일자 상관없이 모든 컬럼의 각 달의 평균을 구하여라
ans = df.groupby(df.Yr_Mo_Dy.dt.month).mean()
ans.head(4)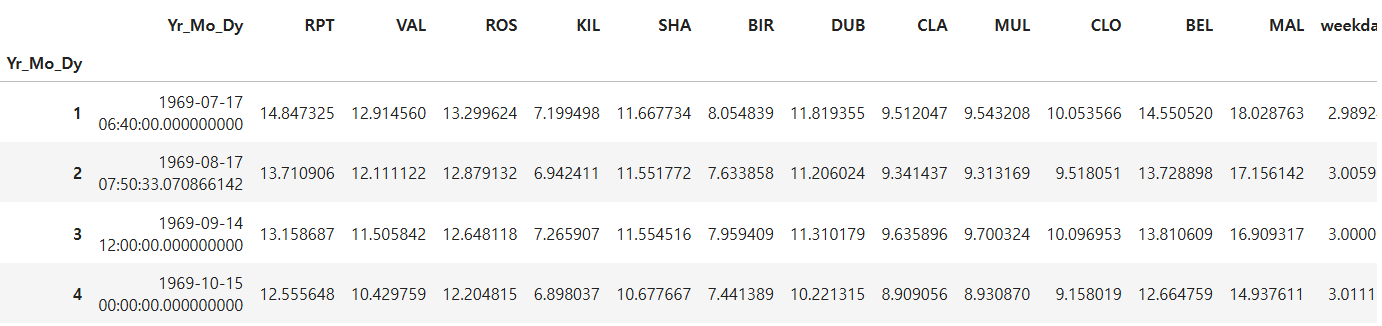
Question 72
모든 결측치는 컬럼기준 직전의 값으로 대체하고 첫번째 행에 결측치가 있을경우 뒤에있는 값으로 대채하라
df = df.fillna(method='ffill').fillna(method='bfill')
df.isnull().sum()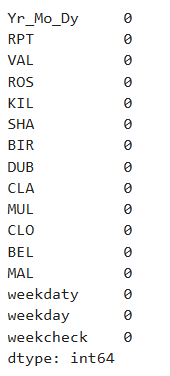
이 코드는 pandas 데이터프레임에서 결측치(누락된 데이터, 즉 NaN 값)를 처리하고, 결측치가 잘 처리되었는지 확인하는 과정입니다. 두 줄로 이루어진 코드를 단계별로 설명하겠습니다.
1. df = df.fillna(method='ffill').fillna(method='bfill')
이 줄은 결측치를 전방 채우기(ffill)와 후방 채우기(bfill) 방식으로 처리합니다.
- fillna(method='ffill'):
- ffill 또는 "forward fill" 방식은 결측치(NaN)가 있는 경우, 그 결측치 바로 앞에 있는 유효한 값을 채워 넣는 방식입니다.
- 예를 들어, 데이터가 [1, NaN, NaN, 4]라면, ffill을 적용한 후에는 [1, 1, 1, 4]로 변환됩니다.
- fillna(method='bfill'):
- bfill 또는 "backward fill" 방식은 결측치 바로 뒤에 있는 유효한 값으로 결측치를 채우는 방식입니다.
- 예를 들어, 데이터가 [1, NaN, NaN, 4]라면, bfill을 적용한 후에는 [1, 4, 4, 4]로 변환됩니다.
Question 73
년도 - 월을 기준으로 모든 컬럼의 평균값을 구하여라
Ans = df.groupby(df.Yr_Mo_Dy.dt.to_period('M')).mean()
Ans.head(3)
Question 74
RPT 컬럼의 값을 일자별 기준으로 1차차분하라
Ans = df['RPT'].diff()
Ans.head(3)

1차 차분은 연속된 시점 간의 차이를 계산하여 시계열 데이터를 변환하는 기법입니다. 주로 시계열 데이터에서 추세를 제거하거나 정상성을 확보하기 위해 사용되며, 데이터의 변화율과 변동성을 분석하는 데 유용합니다.
Question 75
RPT와 VAL의 컬럼을 일주일 간격으로 각각 이동평균한값을 구하여라
ans = df[['RPT','VAL']].rolling(7).mean()
.rolling(7)
- rolling() 함수는 **이동 창(rolling window)**을 생성하는 함수입니다.
- rolling(7)은 7개의 데이터씩 그룹화된 이동 창을 만들어 각 창의 값을 계산하도록 설정합니다. 여기서 7은 창의 크기를 의미하며, 7일 또는 7개의 데이터 단위로 계산을 하겠다는 뜻입니다.
- 이동 창은 데이터를 순차적으로 겹치면서 계산되기 때문에, 첫 번째 7개의 데이터를 하나의 창으로 묶어 평균을 계산하고, 다음에는 한 칸씩 옮기며 다시 평균을 계산하는 방식입니다.
.mean()
- mean() 함수는 각 이동 창의 평균 값을 계산합니다.
- 7개의 데이터로 구성된 각 창에서 RPT와 VAL의 평균을 계산하여 새로운 값을 반환합니다