
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- OPIC 시험 전날
- 강화학습 간단 정리
- OPIC 번개
- ImportError: cannot import name 'Mapping' from 'collections'
- OPIC 하루전 시작
- tensorboard html5
- 공개키 docker
- dice loss
- focal loss
- AI모델
- ollama
- 음성전처리 #음성처리 #python 음성추출 # python 음성 추출 #moviepy
- OPIC 하루 전
- gpt excel 사용
- AI생성함
- tesorboard
- 인간종말
- docker 환경 문제
- 일기 #다짐
- reinforced learning
- ImportError: cannot import name 'Mapping' from 'collections' tensrorbaord
- cross entoropy
- 엑셀에 ollama
- 빅데이터 분석기사 #빅분기실기 #데이터마님 # 빅분기실기준비
- OPIC 당일치기
- DDPG
- tersorboard mapping
- tensorboard 에러
- OPIC 오늘 시작
- whisper jax
Archives
- Today
- Total
Moonie
OpenAI 음성인식 Whisper - Robust Speech Recognition via Large-Scale Weak Supervision 논문 리뷰 본문
공부/논문 리뷰
OpenAI 음성인식 Whisper - Robust Speech Recognition via Large-Scale Weak Supervision 논문 리뷰
Moonie' 2023. 5. 25. 00:43반응형
Abstract
- 단순히 인터넷에서 대량의 오디오 대본을 예측하도록 훈련된 음성 처리 시스템의 기능을 연구합니다.
- 680,000 시간의 다국어 및 multitask supervision 으로 확장될 떄 결과 모델은 표준 벤치마크로 잘 일반화 됨
- 이전 fully supervised 결과와 종종 경쟁적이지만 미세 조정(fine tuning)이 필요 없는 제로 샷 전송 설정
1. Introduction
- 기존 데이터 셋들에 대한 설명(중략)
- 기존 데이터 새트는 기존의 고품질 데이터 세트의 합계보다 몇 배 더 클 뿐이며 이전 비지도 작업(unsupervised work) 보다 여전히 훨씬 데이터 양이 작음.
- weakly supervised speech recognition을 680,000 시간의 레이블된 오디오 데이터이터로 격차를 좁힘
- 이 접근 방식을 Whisper 라고 부름
- 이 규모에서 훈련된 모델이 기존 데이터 세트에 제로샷으로 잘 transfer되어 고품질 결과를 달성하기 위해 데이터 세트별 미세 조정이 필요하지 않음을 보여줍니다.
- weakly supervised pre-training의 범위를 영어 전용 음성 인식을 넘어 다국어 및 멀티태스킹으로 확장하는 데 중점을 둠.
- 680,000 시간의 오디오 중 117,000 시간이 96개의 다른 언어를 다룸
- 데이터 셋에는 125,00시간의 X --> en 번역 데이터도 포함
- 충분히 큰 모델의 경우 다국어 및 멀티태스킹 joint(두개 다 동시에 훈련을 의미) 훈련에 단점이 없으며 이점이 있음을 발견
- 최근 대규모 음성인식 작업의 주축이 되어온 self-supervision 이나 self-training 기법 없이도 좋은 결과를 얻을 수 있음
2. Approach
2.1. Data Processing
- 기계 학습 시스템을 교육하기 위해 인터넷의 웹 규모 텍스트를 활용하는 최근 작업의 추세에 따라 데이터 전처리에 대한 최소한의 접근 방식을 취합니다.
- 대부분의 음성 인식 작업과 달리 발화(utterances)와 전사(transcribe)된 형태 맵핑을 학습하도록 시퀀스-투-시퀀스 모델의 표현력에 의존합니다. 이는 음성 인식 파이프라인을 단순화시키기 때문에, 자연스러운 전사를 생성하기 위한 별도의 역 텍스트 정규화 단계가 필요 없습니다.
- 인터넷 대본과 쌍을 이루는 오디오에서 데이터 세트를 구성, 그 결과 다양한 환경, 녹음 설정, 스피커 및 언어의 광범위한 오디오 분포를 다루는 매우 다양한 데이터 세트가 생성
- 오디오 품질의 다양성은 모델을 견고하게 하지만 전사(transcribe) 품질의 다양성은 좋지 않았음
- 초기 검사에서는 raw dataset에서 수준 이하의 결과가 많이 나타나 이를 개선하기 위해 몇 가지 자동화된 필터링 방법을 개발
- 최근 연구에 따르면 사람과 기계가 혼합한 데이터 세트에 대한 교육은 번역 시스템의 성능을 크게 저하시킬 수 있음
(Ghorbani et al., 2021). - "transcript-ese" 학습을 피하기 위해 우리는 훈련 데이터 세트에서 머신 생성 트랜스크립트를 감지하고 제거하는 많은 휴리스틱을 개발했습니다.
- 기존의 많은ASR 시스템은 복잡한 구두점(느낌표, 쉼표, 물음표), 단락과 같은 포맷의 공백, 대문자 사용 등과 같은 스타일적 측면과 같이 오디오 신호만으로 예측하기 어려운 측면을 제거하거나 정규화하는 한정된 쓰여진 언어의 부분 집합만 출력합니다.
--> 모두 대문자 또는 모두 소문자로 된 transcript(글로 옮긴 기록)는 사람이 생성한 것일 가능성이 매우 낮습니다. 많은 ASR 시스템에는 일정 수준의 역 텍스트 정규화가 포함되어 있지만 단순하거나 규칙 기반인 경우가 많으며 쉼표를 포함하지 않는 등 처리되지 않은 다른 측면에서 여전히 감지할 수 있습니다. - 우리는 오디오 언어 감지기를 사용합니다. 이는 데이터셋의 프로토타입 버전에서 훈련된 프로토타입 모델을 미세조정하여 VoxLingua107 (Valk & Aluma, 2021)에서 생성되었습니다. 이는 말한 언어가 CLD2(Compact Language Detector 2)에 따른 전사본의 언어와 일치하는지 확인합니다.
- 두 가지가 일치하지 않으면, 우리는 (오디오, 전사본) 쌍을 데이터셋의 음성 인식 훈련 예제로 포함하지 않습니다. 전사본 언어가 영어인 경우에는 예외를 만들고 이들 쌍을 X→en 음성 번역 훈련 예제로 대신 추가합니다. 전사본 텍스트의 퍼지 중복 제거를 사용하여 훈련 데이터셋의 중복과 자동 생성된 내용을 줄입니다.
- 우리는 오디오 파일을 30초 단위의 세그먼트로 나누고, 그 시간 세그먼트 내에서 발생하는 전사본의 부분 집합과 쌍을 이룹니다. 우리는 모든 오디오, 즉 음성이 없는 세그먼트도 (확률이 낮게 샘플링되지만) 훈련하고 이러한 세그먼트를 음성 활동 감지의 훈련 데이터로 사용합니다.
- 추가적인 필터링 패스를 위해, 초기 모델을 훈련한 후에 우리는 훈련 데이터 소스에서의 그 오류율에 대한 정보를 집계하고, 높은 오류율과 데이터 소스 크기의 조합으로 이들 데이터 소스를 정렬하여 효율적으로 낮은 품질의 것들을 식별하고 제거하는 수동 검사를 수행했습니다. 이 검사에서는 필터링 휴리스틱이 감지하지 못한 부분적으로 전사되거나 정렬이 잘못되거나 미정렬된 전사본 및 남아 있는 저품질의 기계 생성 캡션의 대량이 발견되었습니다. 오염을 피하기 위해, 우리는 훈련 데이터셋과 높은 중복 위험이 있는 평가 데이터셋, 즉 TED-LIUM 3 (Hernandez 등, 2018) 사이에서 전사본 수준에서 중복 제거를 수행합니다
- 2.1. 부분 요약
이 연구에서는 웹 규모의 텍스트를 사용한 최근의 연구 추세를 따라 데이터 전처리를 최소화하는 방식으로 Whisper 모델을 훈련시키고 있습니다. 이 모델은 주요 표준화 없이 원시 텍스트를 예측하도록 설계되어 있으며, 음성 인식 파이프라인을 단순화합니다. (Sequence-to-Sequence 사용)
데이터셋은 인터넷에서 쌍을 이루는 오디오와 전사본을 활용하여 구축하며, 이는 다양한 환경, 녹음 설정, 화자, 언어에서 온 오디오를 포함합니다. 오디오 품질의 다양성은 모델을 강화하는 데 도움이 되지만, 전사 품질의 다양성은 그렇지 않습니다. 따라서 원시 데이터셋의 낮은 품질의 전사본을 개선하기 위해 자동 필터링 방법을 개발했습니다.
또한, 기계가 생성한 전사본을 훈련 데이터셋에서 감지하고 제거하기 위한 휴리스틱을 개발하였습니다. 오디오 언어 감지기를 사용하여 말한 언어가 전사본의 언어와 일치하는지 확인하고, 일치하지 않는 경우는 데이터셋에서 제외합니다. 전사본의 중복 및 자동 생성된 내용을 줄이기 위해 퍼지 중복 제거를 사용합니다.
오디오 파일을 30초 세그먼트로 분할하고, 해당 시간 세그먼트 내에서 발생하는 전사본의 부분과 쌍을 이루어 훈련에 사용합니다. 초기 모델 훈련 후에는 훈련 데이터 소스의 오류율 정보를 집계하고, 이를 바탕으로 수동 검사를 수행하여 낮은 품질의 데이터 소스를 식별하고 제거합니다. 마지막으로, 훈련 데이터셋과 중복 위험이 높은 평가 데이터셋 사이에서 전사본 수준에서 중복 제거를 수행하여 데이터 오염을 방지합니다.
2.2 Model
- 연구 중점은 음성 인식을 위한 대규모 지도학습 사전 훈련의 능력에 대한 연구이므로, 모델 개선과 발견이 혼동되는 것을 피하기 위해 준비된 아키텍처를 사용합니다.
- 우리는 이 아키텍처가 안정적으로 확장되는 데 잘 검증되었기 때문에 인코더-디코더 트랜스포머(Vaswani et al., 2017)를 선택했습니다.
- 모든 오디오는 16,000 Hz로 재샘플링되며, 80-채널 로그 크기 Mel 스펙트로그램 표현은 25-밀리초 윈도우에서 10-밀리초 스트라이드로 계산됩니다.
- 특성 정규화를 위해, 우리는 사전 훈련 데이터셋 전체에서 대략적으로 평균이 0이 되도록 입력을 -1과 1 사이로 전역적으로 조정합니다.
- 인코더는 이 입력 표현을 필터 너비가 3이며 GELU 활성화 함수(Hendrycks & Gimpel, 2016)를 가진 두 개의 합성곱 레이어로 구성된 작은 줄기로 처리하는데, 여기서 두 번째 합성곱 레이어는 스트라이드가 두 개입니다.
- 그 다음, sinusoidal position embedding이 줄기(stem)의 출력에 추가되고, 그 다음에 인코더 트랜스포머 블록이 적용됩니다.
- 트랜스포머는 pre-activation residual blocks(Child 등, 2019)을 사용하며, 최종 레이어 정규화가 인코더 출력에 적용됩니다.
- 디코더는 학습된 위치 임베딩과 결합된 입력-출력 토큰 표현(Press & Wolf, 2017)을 사용합니다.
- 인코더와 디코더는 동일한 너비와 트랜스포머 블록 수를 가지고 있습니다. 그림 1은 모델 아키텍처를 요약하고 있습니다.
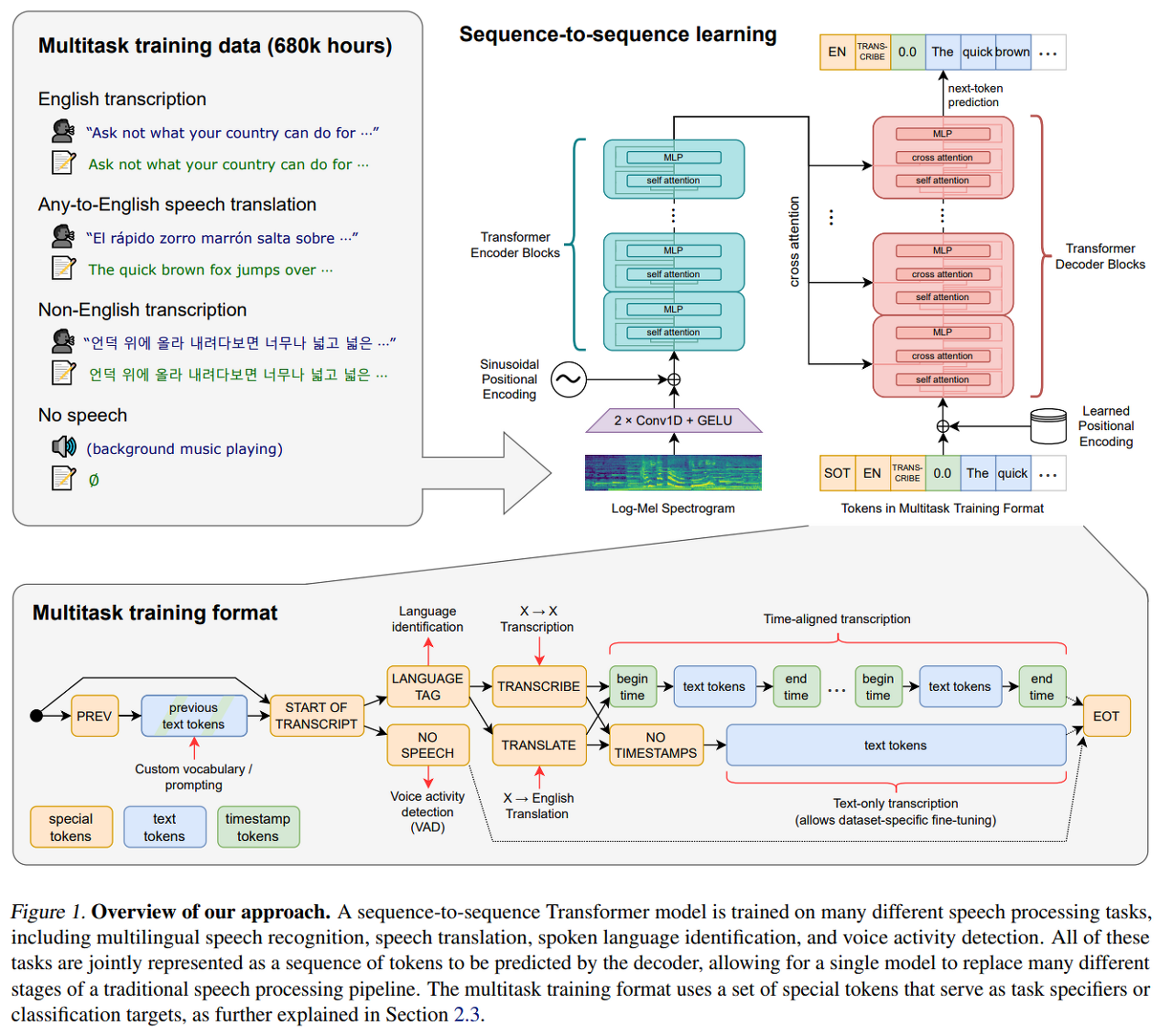
2.3. Multitask Format
- 어떤 오디오 스니펫(audio snippet, snippet은 조각이라는 의미로 여기서는 오디오 데이터 조각이라 뜻하는게 맞다 생각함)에서 어떤 단어가 발화되었는지 예측하는 것은 전체 음성 인식 문제의 핵심 부분이며, 연구에서도 광범위하게 연구되고 있지만, 이것만이 전부는 아닙니다. 완전한 기능을 가진 음성 인식 시스템은 음성 활동 감지, 화자 구분, 역문자 정규화 등 많은 추가 구성 요소를 포함할 수 있습니다.
- 이러한 구성 요소들은 종종 별도로 처리되어 핵심 음성 인식 모델을 중심으로 상대적으로 복잡한 시스템이 구성. 이러한 복잡성을 줄이기 위해 우리는 핵심 인식 부분뿐만 아니라 전체 음성 처리 파이프라인을 수행하는 단일 모델을 가지고 싶음. 여기서 중요한 고려 사항은 모델의 인터페이스입니다. 같은 입력 오디오 신호에 대해 수행할 수 있는 다양한 작업들이 있습니다: 전사(transcription), 번역(translation), 음성 활동 감지(voice activity detection), 정렬(alignment), 언어 식별 (language identification)등이 그 예입니다.
- 단일 모델에서 이런 일대다 매핑을 작동시키려면, 어떤 형태의 작업 지정이 필요합니다. 우리는 모든 작업과 조건 정보를 디코더의 입력 토큰 시퀀스로 지정하는 간단한 형식을 사용합니다.
- 우리의 디코더는 오디오 조건부 언어 모델이므로, 더 긴 범위의 텍스트 컨텍스트를 사용하여 모호한 오디오를 해결할 수 있도록 학습하게 만듬.
- 특히, 일부 확률로 현재 오디오 세그먼트 앞의 전사 텍스트를 디코더의 컨텍스트에 추가합니다. 우리는 <|startoftranscript|> 예측의 시작을 토큰으로 표시.
- 먼저, 우리는 훈련 세트에서 각 언어를 대표하는 고유 토큰으로 언어를 예측(총 99개).이 언어 목표는 앞서 언급한 VoxLingua107 모델에서 출처를 찾음.
- 오디오 세그먼트에서 음성이 없는 경우, 모델은 <|nospeech|>를 나타내는 토큰을 예측하도록 학습.
- 다음 토큰은 작업을 <|transcribe|> 또는 <|translate|>토큰으로 지정.
- 이후에는 타임스탬프를 예측할지 여부를 <|notimestamps|>토큰을 포함하여 지정합니다. 이 시점에서 작업과 원하는 형식이 완전히 지정되고, 출력이 시작.
- 타임스탬프 예측의 경우, 현재 오디오 세그먼트에 대한 상대적인 시간을 예측하며, 모든 시간을 Whisper 모델의 기본 시간 해상도와 일치하는 가장 가까운 20 밀리초로 양자화하고, 각각에 대한 추가 토큰을 우리의 어휘에 추가합니다.
- 모델은 예측을 캡션 토큰과 교차하게 함: 시작 시간 토큰은 각 캡션의 텍스트 전에 예측되며, 종료 시간 토큰은 이후에 예측됩니다. 최종 전사 세그먼트가 현재 30초 오디오 청크에 부분적으로만 포함되어 있는 경우, 타임스탬프 모드에서 세그먼트에 대한 시작 시간 토큰만을 예측하여 그 후의 디코딩이 해당 시간에 맞춰진 오디오 창에서 수행되어야 함을 나타내며, 그렇지 않으면 우리는 세그먼트를 포함하지 않도록 오디오를 자릅니다.
- 마지막으로, <|endoftranscript|>토큰을 추가합니다.
- 이전 컨텍스트 텍스트 위의 training loss만 마스크하고, 모델을 모든 다른 토큰을 예측하도록 학습시킴.
2.4.Training Details
- Whisper 모델의 스케일링 속성을 연구하기 위해 다양한 크기의 모델을 훈련했습니다. 테이블 1을 참조.
- FP16를 사용하여 가속기 간 데이터 병렬성을 활용하여 훈련하고, dynamic loss 스케일링과 activation 체크포인트를 사용했습니다.
- AdamW와 gradient norm clipping을 사용하여 학습률을 2048번의 업데이트를 거친 후에 0으로 linear learning rate decay 시켰습니다.
- 256 세그먼트의 배치 크기를 사용했고, 모델은 데이터셋을 2-3번 훑는 것과 같은 2^20번의 업데이트를 위해 학습 됨.
- 몇 번의 에포크만 훈련하기 때문에 과적합은 큰 문제가 아니었으며, 데이터 증가나 정규화는 사용하지 않고 대신 큰 데이터셋 내의 다양성에 의존하여 일반화와 견고성을 증가시켰습니다.
- 초기 개발 및 평가 도중 Whisper 모델이 화자의 이름을 그럴듯하게 하지만 거의 항상 잘못된 추측으로 전사하는 경향을 보였습니다. 이것은 훈련 데이터셋의 많은 전사가 말하는 사람의 이름을 포함하고 있기 때문에 모델이 그들을 예측하려는 경향이 있지만, 이 정보는 가장 최근의 30초 오디오 컨텍스트에서만은 거의 추론할 수 없음.
- 이를 피하기 위해, 우리는 화자 주석이 포함되지 않은 전사의 하위 집합에서 Whisper 모델을 짧게 fine-tune하여 이런 행동을 제거.

반응형
'공부 > 논문 리뷰' 카테고리의 다른 글
| [음성 인식] WAV2VEC: UNSUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION (0) | 2023.04.27 |
|---|
'공부/논문 리뷰' Related Articles
more

Comments